Stable Diffusion 模型生态
尚未完成,持续更新
To Categorize
- Embeddings
- Dreambooth Checkpoint
- LoCon / LoHa / LyCORIS
- T2I Adapter
- Wonder 3D
- AnimateDiff
- LCM / LCM LoRA
- Consistency Decoder
- AnimateAnyone
- MagicAnimate
Others
- DreamGaussion
- Stable Video Diffusion
Original Stable Diffusion
High-Resolution Image Synthesis with Latent Diffusion Models
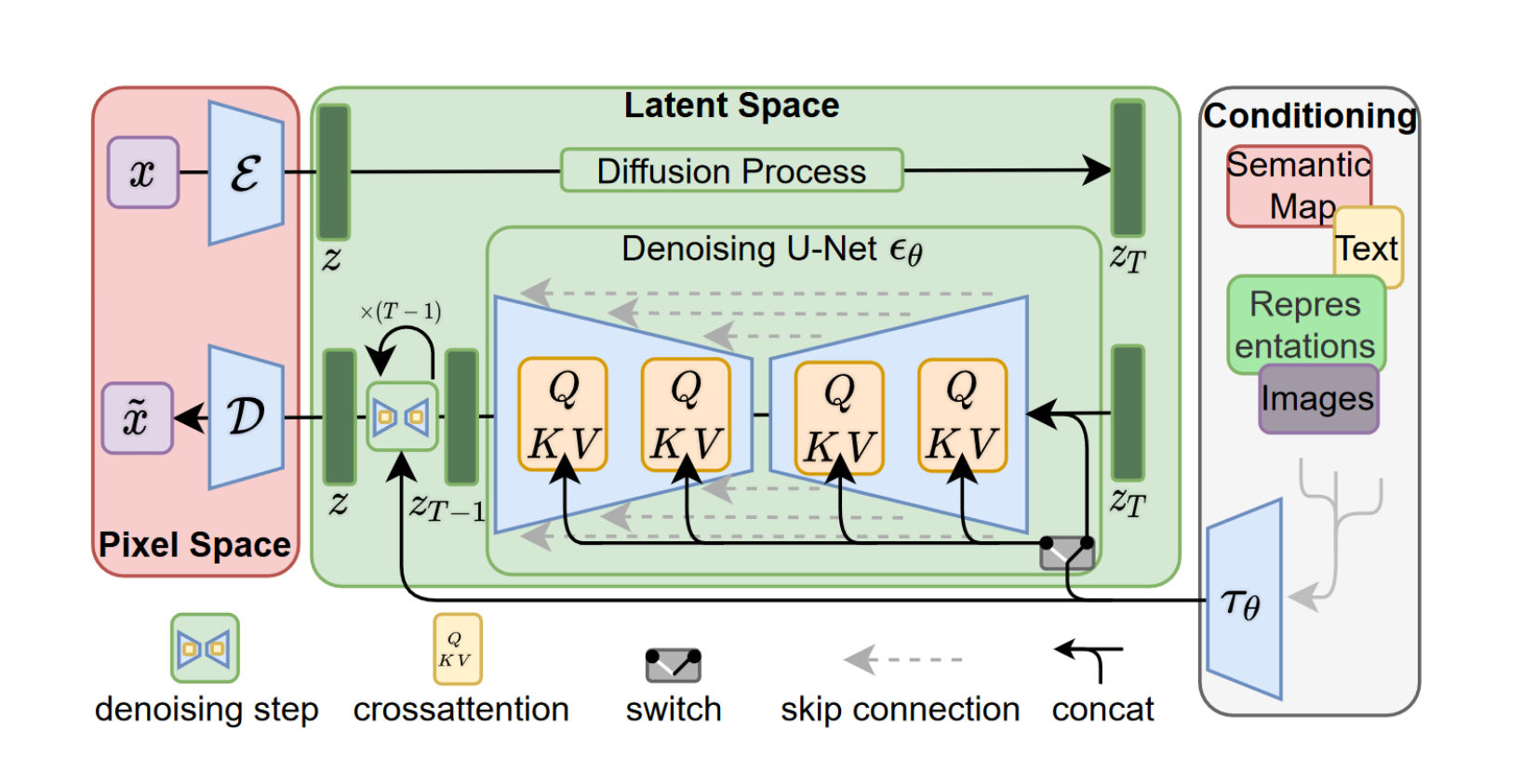
本质上是一个去噪的过程,做了三件事情,一是训练了一个从噪声中想象图像的网络(UNet),二是通过注意力机制让文字引导去噪过程(Spatial Trasformer),三是把整个去噪的过程从像素空间迁移到 Latent 空间(通过 VAE),所以 Stable Diffusion 分类上是一个 LDM 模型(Latent Diffusion Model)
App
- AI Comic Factory https://huggingface.co/spaces/jbilcke-hf/ai-comic-factory
- Try Emoji https://huggingface.co/spaces/leptonai/tryemoji
- IllusionDiffusion https://huggingface.co/spaces/AP123/IllusionDiffusion
- PixArt LCM https://huggingface.co/spaces/PixArt-alpha/PixArt-LCM
ControlNet
Adding Conditional Control to Text-to-Image Diffusion Models
- lllyasviel/ControlNet: Let us control diffusion models!
- lllyasviel/ControlNet-v1-1-nightly: Nightly release of ControlNet 1.1
- ControlNet in 🧨 Diffusers
- ControlNet
- Train your ControlNet with diffusers
- ControlNet
LoRA
LoRA: Low-Rank Adaptation of Large Language Models
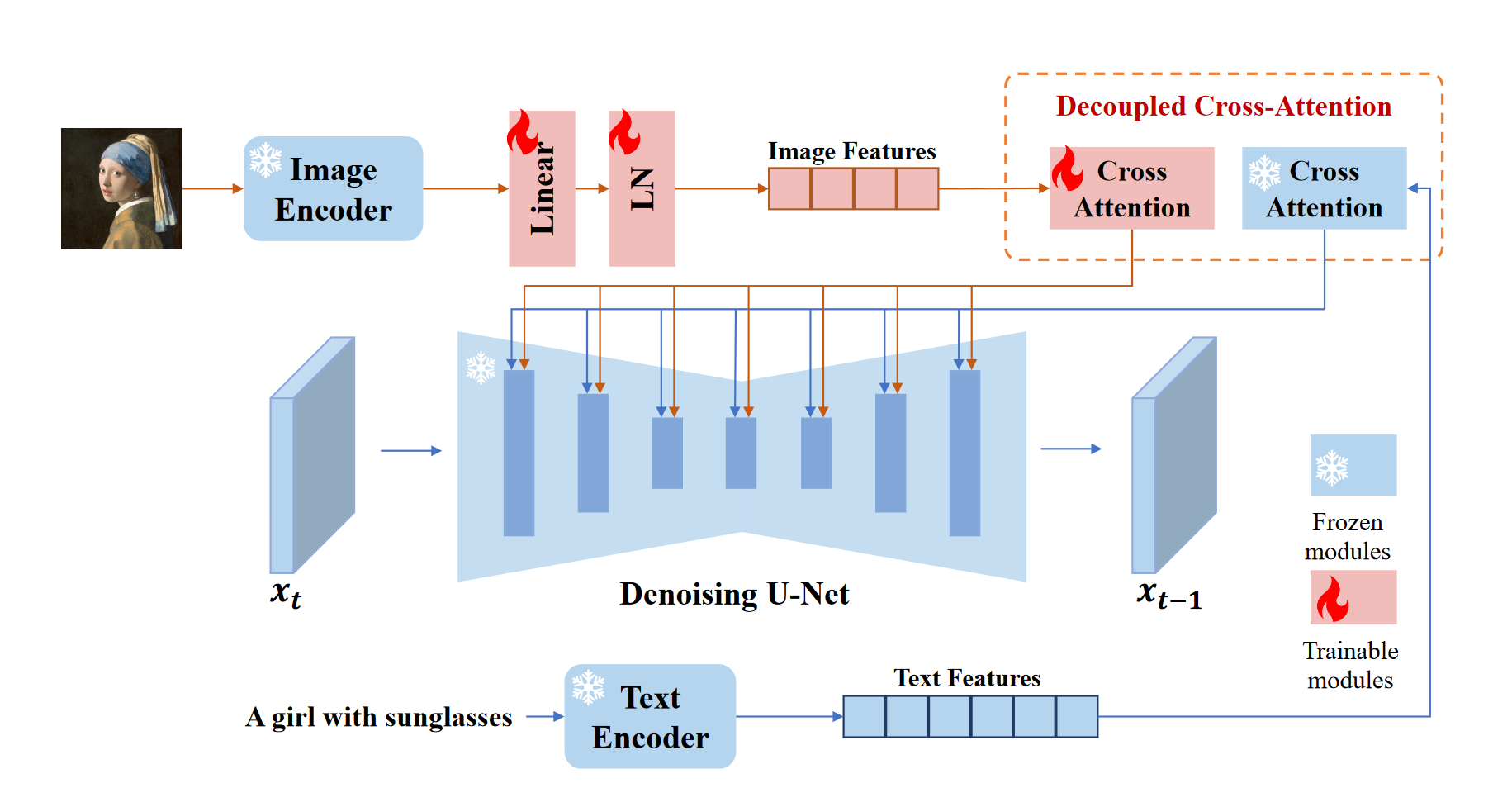
IP Adapter
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
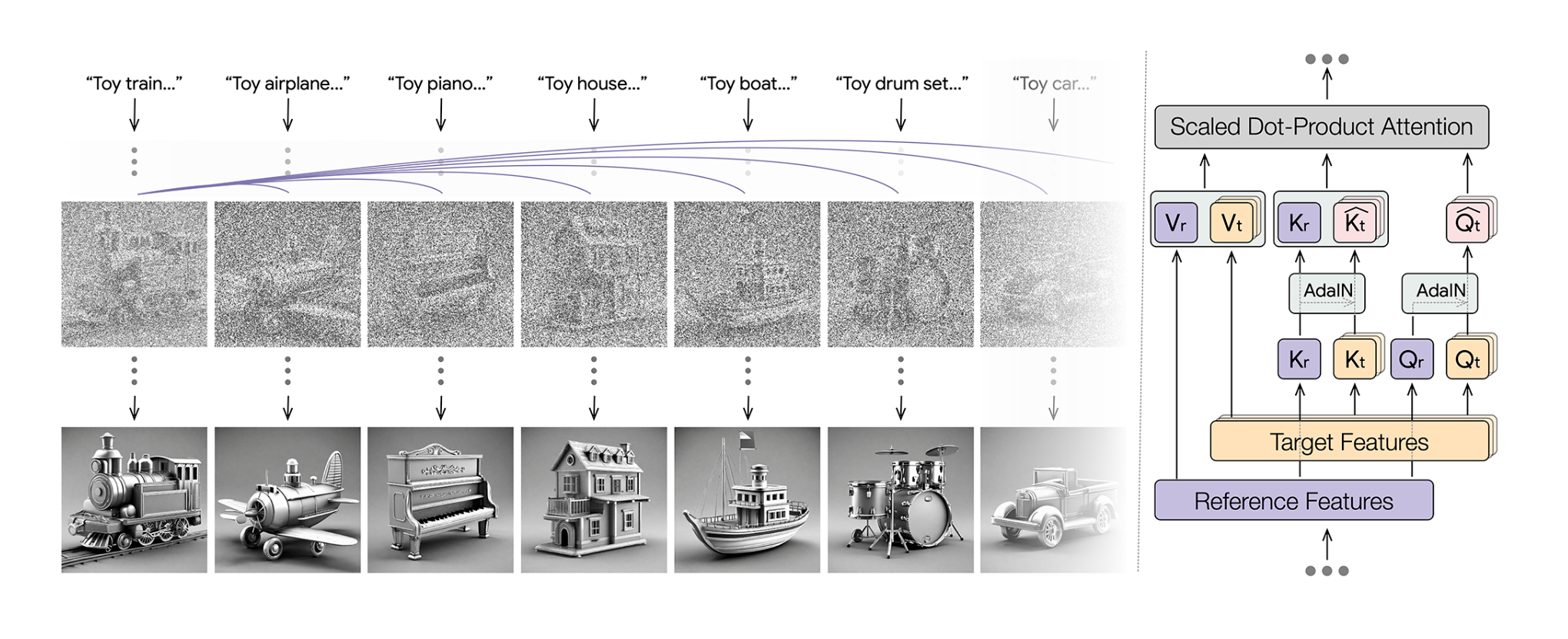
Style Aligned Generation
Style Aligned Image Generation via Shared Attention
https://style-aligned-gen.github.io https://github.com/google/style-aligned/blob/main/style_aligned_sdxl.ipynb
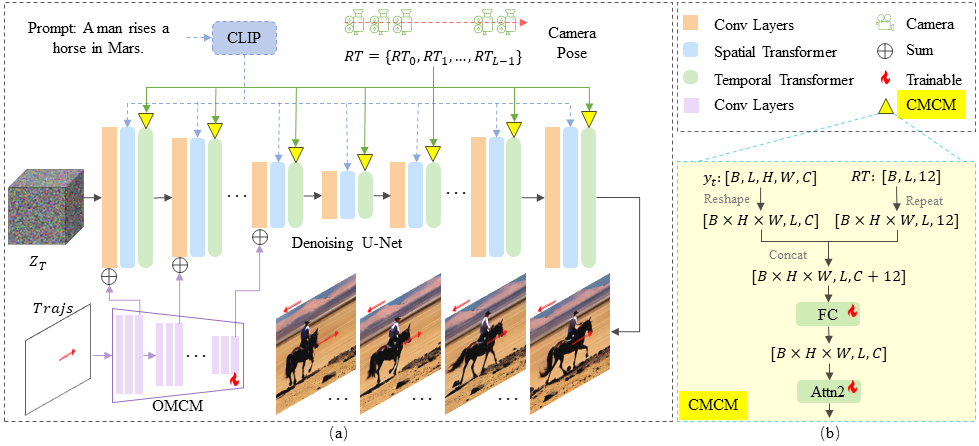
MagicAnimate
MotionCtrl
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation